

Have you wondered how to create automated reports and dashboards in R?
Are there certain dashboards, reports, and presentations that show the same analysis for different categories or regions?
Every time the data changes do you have to recalculate the numbers, recreate the charts, and design the slides? Did you wish for an automated statistical reporting system?
Look no further: in this article, you will see the power of R, rmarkdown, and LaTex to create beautiful looking dashboards, reports, and presentations.
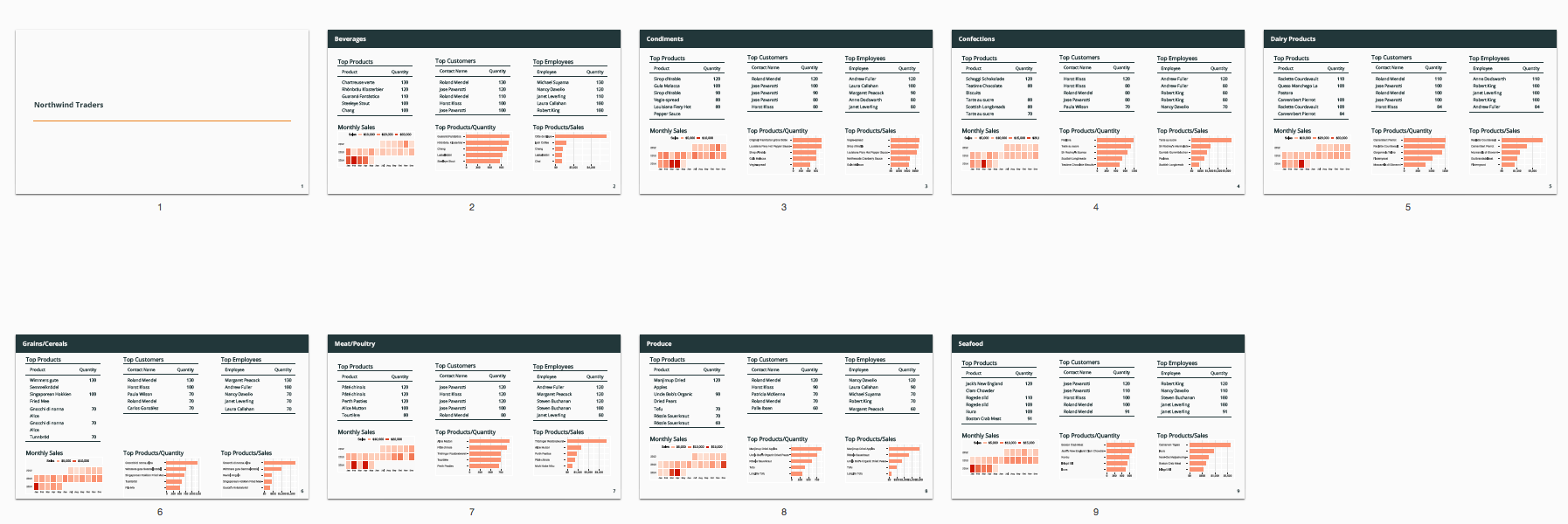
See this beautiful dashboard that we will create in this article.

Some other little new things you may learn in this article:
- How to create a calendar heat map in R?
- How to use the kableExtra package to make your tables look nice?
- How to connect to databases in R?
- How to use SQL to connect to a database?
- How to make your ggplot graphs clean?
I just want to warn, however, that this article is not for beginners because it does involve some trickery with LaTex, a typesetting language. To get my final dashboard, I spent hours struggling with the path variable, LaTex packages, and RStudio.
I have all the code set up, but you may face difficulties when you are trying to do this on your own.
Before you get started, make sure that you test your set-up and environment. Make sure your R is up-to-date. Make sure your RStudio is up-to-date. Make sure all your libraries are up-to-date. Make sure you have LaTex typesetting packages installed: MikTex for Windows and MacTex for MacOS.
You may want to test them by creating a simple, minimal example using a typesetting program like TexMaker or by creating a rmarkdown document in RStudio and adding some LaTex commands to it.
For this article, we will use the Northwind database that Microsoft provides with its Access database and the SQL Server database. Luckily for us, JP White made an SQLite database off the same tables.
I downloaded this SQLite Northwind database in folder named data. You can either download it or use a direct link.
Let's get started.
Creating Automated Reports and Dashboards in R
I created an RMD document called northwind-master-report.Rmd. You can find this option under File > New and R Markdown document.
I entered the following parameters using the YAML format.
title: "Northwind Traders"
output:
beamer_presentation:
toc: false
keep_tex: true
latex_engine: xelatex
includes:
in_header: nw_report_header.tex
classoption: "aspectratio=169"
I set the output to a Beamer presentation, which is a LaTex template. It's kind of old-school but that's how these presentations were created in LaTex.
I set toc equal to false since I don't want a table of contents.
I'm keeping the tex file, which is generated when you have LaTex code in your rmarkdown documents, just to debug and to see any errors.
I'm using the xelatex LaTex engine because it gives me more flexibility in terms of specific font types that I want to use.
I set a value for the includes parameter too. It is adding a certain file in the header to every child document. Here's what those LaTex commands look like:
\setbeamertemplate{navigation symbols}{} %remove nav bar
\usepackage{booktabs}
\usepackage{graphicx}
\usetheme{metropolis}
\setsansfont{Open Sans}
\newenvironment<>{varblock}[2][.95\textwidth]{%
\setlength{\textwidth}{#1}
\begin{actionenv}#3%
\def\insertblocktitle{#2}%
\par%
\usebeamertemplate{block begin}}
{\par%
\usebeamertemplate{block end}%
\end{actionenv}}
\usepackage{array}
You don't have to worry too much about this: these are just some shortcuts and commands that I want to use in the individual documents. You can copy and paste this as is. I know I copied a lot of code from StackOverflow.
But I will try to explain these one line at a time:
The first line turns off the navigation symbols because, by default, the Beamer templates create navigation symbols.
booktabs create nice-looking tables.
graphicx is a package that lets us include images and PDFs.
I'm using the metropolis theme which comes with the Beamer template.
I am also setting the font type to "open sans" from Google Fonts. I downloaded and installed this font on my machine.
Don't worry about the rest of the code: I most likely copied this from somewhere too. This adds the proper title up at the top.
The last command is for the array package which helps us create different columns.
Let's go back to our master document. I named it master because this file contains all the code that we need to create our report.
The last option in our YAML is to set the aspect ratio. By default, beamer creates four by three documents with the aspect ratio of four by three, but sixteen by nine gives us more space. It looks better too.
Let's get into the code.
R Code for Automated Reports
First up, we have an R chunk (aka code block), called setup. I have set the parameter of include to false because we don't want this code to actually show up in the document.
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = FALSE,
warning = FALSE,
message = FALSE,
fig.showtext = TRUE)
options(tinytex.verbose = TRUE)
library(tidyverse)
library(knitr)
library(kableExtra)
library(lubridate)
library(scales)
library(showtext)
font.add("opensans", regular = "OpenSans-Regular.ttf")
showtext.auto()
We don't want to show this code in our final document. We don't want to show any warnings. We don't want to see any messages.
When you change the font type in a Rmarkdown document, only the LaTex document or the rmarkdown document will change the font type, but the figures or the plots that are created using R would still have the original font. To change the font type on the graphs, we are setting fig.showtext = TRUE.
Next up, we are loading our favorite libraries.
tidyverse to get all the wonderful libraries: dplyr, stringer and various other libraries that we will be using in this code.
knitr to knit this document.
kableExtra to make pretty tables -- this is a pretty cool library and you can see all great examples on their website.
lubridate to modify the dates.
scales is to add different labels on the plots as well as for some static functions for number formatting like percent, dollar or comma.
showtext for us to use any font type that's installed on your machine. I've set the font to open sans. Once you say show.text(auto), it will automatically use the font type you have selected on every chart, so you don't have to keep adding that to every ggplot.
On this Github page, you can see the Northwind database samples in SQLLite format. You can also see the entity-relationship diagram that shows the relationships among different tables i.e. how are they connected and what the primary keys are. Thank you, JP white, for creating this database for us.
The DBI package, as the description says, allows us to connect to various relational database management systems. If you don't want to load a library, you can use the package name and two colons to use the functions from that library.
We're using the dbConnect function to connect to our SQLLite database. It needs the driver, any authentication details including username and password. Here, I selected the SQLite driver and the database is in the data folder. Once you get the connection established, you can use the dbListTables function to see all the tables contained in the database.
nw_db_con <- DBI::dbConnect(RSQLite::SQLite(), dbname = "data/Northwind_small.sqlite")
Using this connection, I am running a SQL query to get the relevant data. I used the entity-relationship diagram from the Github page and joined the different tables. You can chain in dplyr commands too. My SQL query may not make sense, but for this post's sake, it will work.
nw_data <- nw_db_con %>%
tbl(sql("SELECT c.categoryname,
p.productname,
od.unitprice,
od.quantity,
cu.contactname,
e.region,
e.firstname || ' ' || e.lastname AS EmpName,
o.orderdate
FROM category c
INNER JOIN product p
ON c.id = p.categoryid
INNER JOIN orderdetail od
ON p.id = od.productid
INNER JOIN [order] o
ON od.orderid = o.id
INNER JOIN customer cu
ON o.customerid = cu.id
INNER JOIN employee e
ON o.employeeid = e.id"
)
) %>%
collect()
We store the results of the query in the nw_data data frame. I noticed that the order dates didn't come in a date format, so I changed using the mutate command from dplyr to change the order date and put it in the YYYY-MM-DD format.
nw_data <- mutate(nw_data, OrderDate = as.Date(OrderDate, format = "%Y-%m-%d"))
cat_counts <- count(nw_data, CategoryName)
The cat_counts data frame stores the number of rows in each of the categories. We will use these categories as our main breakdown measures. We will show the top products, customers, employees, and some other sales data for each category. We have eight categories including beverages, condiments, and others.
Next up is the long function for creating a calendar heat map. The function takes in various values for the x-variable, y-variable, fill-variable, format for the numbers, and the legend title.
my_calendarheatmap <- function(df, xvar, yearvar, fillvar, fillvarformat = comma, legendtitle) {
g <- ggplot(df, aes_string(x = xvar, y = yearvar, fill = fillvar)) +
geom_tile(colour = "white") +
scale_fill_gradientn(colors = c("#fee0d2", "#fc9272", '#CC0000'),
breaks = pretty_breaks(3),
label = fillvarformat)
g <- g + theme_bw() +
theme(axis.ticks = element_blank(),
legend.position = "top",
panel.border = element_blank(),
panel.grid = element_blank(),
legend.key = element_blank(),
legend.margin = unit(-0.4, "lines"),
plot.margin = unit(c(0.5, 0.1, 0.15, 0.1), "lines")
)
g <- g + theme(axis.title = element_blank(),
legend.text = element_text(size = rel(1)),
axis.text.x = element_text(margin = margin(t = -5, b = 0.5))
)
g + scale_x_continuous(breaks = 1:12,
labels = month.abb,
expand = c(0, 0)) +
scale_y_reverse(breaks = min(df[[yearvar]]):max(df[[yearvar]])) +
guides(fill = guide_legend(keywidth = rel(1),
keyheight = rel(0.5),
title = legendtitle,
direction = "horizontal"
))
}
```
Let's walk through this function.
You will notice that we are using aes_string instead of the regular aes function. We need to use that function because passing variables don't work with the regular aes function. We are generating tiles for each data point and we are filling them with the gradient of colors from orange to dark red.
We are making changes to other theme elements to remove the tick marks, move the legend to top, and remove the panel and plot backgrounds. We want to add breaks on the x-axis make for each of the months using the month.abb stored variable.
This function will create a heatmap plot showing a measure for every month, with darker colors for higher values and lighter colors for lower values.
We have placed this function in our master RMD document, and when we knit this document, knitr will go through all of this and generate a PDF for us. But we need to add some category specific data.
The knitr library comes with a nifty function called knit_child. This function knits a child document and returns a character string that we can feed into our master document.
We define a variable called out. Initially, we set it to NULL, but in every loop, knit_child will knit a document and return a string. We will concatenate this string with the out variable.
```{r runall, include=FALSE}
out <- NULL
for (i in 1:2) {
out <- c(out, knitr::knit_child('northwind-child-report.Rmd'))
}
```
Currently, the loop is set to be run twice, selecting two categories. The out variable has the rmarkdown markup for two categories.
As the last step, we need to print this markup. We do so using the paste command and collapsing the markup using a newline separator.
`r paste(out, collapse = '\n')`
The child document
All the magic is happening inside this child document. In this document, we define how our presentation should look like.
The Beamer class document for a presentation offers a columns functionality. You can divide a slide into n number of columns. For this report, we want to create two rows and three columns, with six boxes or containers for us to place data or charts.
The first thing we do is set up the data for the calculations for each of the slides.
In our master RMD document, we are passing the value of our iterator (i) in the for loop to the child document. We use the value of i to select the category from the cat_counts data frame. After converting it to character, we get the category name to use for further filtering and display.
We use the category name as our slide title. But for your data, you could change it to whichever breakdown variable you are using. We store this name in the cat_loop_name variable. We then filter the nw_data data frame for this category and store it in the data frame called data.
```{r, echo=FALSE}
cat_loop_name <- as.character(select(filter(cat_counts, row_number() == i), CategoryName))
data <- filter(nw_data, CategoryName == cat_loop_name)
```
Now on to creating the markdown document.
One pound or hash symbol (#) creates the top-level heading in the document. If it's an article in rmarkdown, it will create a section header. But in this case, it's the slide header. Using the inline R code, we are printing the category name in the slide header.
# `r cat_loop_name`
We will use the columns functionality to create three columns. If you don't know the LaTex markup, check this resource. But it's similar to HTML. We create an opening tag and close it to the same tag.
In this case, it's \begin{columns} and \end{columns}. The parameter T asks LaTex to top-align all of those columns. To get three equal-width columns, we specify the column width as 30% of the text width that it has available. We chose 30% because we want some whitespace among all the columns. Something like this:
#just an example. Don't use this code.
\begin{columns}[T]
\begin{column}{0.30\textwidth}
Top Products
\end{column}
\hfill
\begin{column}{0.30\textwidth}
Top Customers
\end{column}
\hfill
\begin{column}{0.30\textwidth}
Top Employess
\end{column}
\end{columns}
In the first column and first box, we want to see the top five products by quantity sold. We use the arrange function from dplyr to sort the products by quantity. We select the top five rows. We are also using the select function to rename one of the columns.
The kable function will convert the data frame to a LaTex markup which can be as is to create tables. We are using booktab commands to get rules below the top and bottom row.
We specify the column width using the kable_styling function from kableExtra. It is a powerful library, letting us create beautiful tables. You can highlight certain cells and add alternate row colors.
\scriptsize command makes the font size smaller and \normalsize makes the font size to the normal size.
\begin{columns}[T]
\begin{column}{0.30\textwidth} %first column
Top Products
\scriptsize
```{r}
#http://haozhu233.github.io/kableExtra/awesome_table_in_pdf.pdf
arrange(data, desc(Quantity)) %>%
head(n = 5) %>%
select(Product = ProductName, Quantity) %>%
arrange(desc(Quantity)) %>%
kable(format = "latex", booktabs = TRUE) %>%
#kable_styling(latex_options = "striped") %>%
#kable_styling(full_width = F) %>%
column_spec(1, width = "0.9in")
```
\normalsize
\end{column}
\hfill
\begin{column}{0.30\textwidth} %second column
Top Customers
\scriptsize
```{r}
arrange(data, desc(Quantity)) %>%
head(n = 5) %>%
select(`Contact Name`= ContactName, Quantity) %>%
arrange(desc(Quantity)) %>%
kable(format = "latex", booktabs = TRUE) %>%
#kable_styling(latex_options = "striped") %>%
#kable_styling(full_width = F) %>%
column_spec(1, width = "0.9in")
```
\normalsize
\end{column}
\hfill
\begin{column}{0.30\textwidth} %third column
Top Employees
\scriptsize
```{r}
arrange(data, desc(Quantity)) %>%
head(n = 5) %>%
select(Employee = EmpName, Quantity) %>%
arrange(desc(Quantity)) %>%
kable(format = "latex", booktabs = TRUE) %>%
#kable_styling(latex_options = "striped") %>%
#kable_styling(full_width = F) %>%
column_spec(1, width = "0.9in")
```
\normalsize
\end{column}
\end{columns}
\vspace{2em}
In the second box -- the middle column in the top row -- we want to see the top customers. Similar to the top products table, we want to create a table for top customers. And in the last box of the first row, we want to see the top employees responsible for these sales.
We will then close the first row and add some space between the first row and the second-row using \vspace command.
Creating the graphs
For the bottom row, similar to the first row, we will use \begin{columns} and \end{columns}. We will add three \begin{column} for each of the boxes and with 30% text-width.
In the first box of the second row, I want to see monthly sales in the heatmap format using the function we created in the master document. To make sure that the plot shows up with a good resolution, we need to add some extra parameters, such as the width, the plot height, and how much space the plot should take.
Since the order date was in a date format, we will use the month function from lubridate to convert this into a number here by extracting the month. We will also extract the year from the date using the year function. We will then group the data by year and month, and calculate the monthly sales. Once these are calculated, we will pass these to the my_calendarheatmap function. We do so by using the dot notation. The dot represents the data before the current function/command.
We are also passing the monthly sales as a fill variable; the tiles will be darker if the sales are higher and lighter if the sales were lower.
In the middle column for the second row, we want to see the top products by quantity. This is just some silly calculations I actually I created for this post. We select the top five products by quantity sold. A bar graph will show the top five products.
In the last box, we want to see the top product by sales. In the bar graph, we want to see the top five products by the number of sales.
\begin{columns}[T]
\begin{column}{0.30\textwidth} %second row, first column heat map
Monthly Sales
```{r, out.width="\\textwidth", fig.width=3.8,fig.height=1.8,fig.asp=NA}
g <- data %>%
mutate(order_month = month(OrderDate),
order_year = year(OrderDate)) %>%
group_by(order_year, order_month) %>%
summarize(monthly_sales = sum(Quantity * UnitPrice)) %>%
my_calendarheatmap(
df = .,
xvar = "order_month",
y = "order_year",
fillvar = "monthly_sales",
legendtitle = "Sales",
fillvarformat = dollar
)
g + theme(
axis.text.y = element_text(size = rel(1)),
axis.text.x = element_text(size = rel(0.8), face = "bold"),
panel.background = element_rect(fill = "grey98"),
plot.background = element_rect(fill = "grey98")
)
```
\end{column}
\hfill
\begin{column}{0.30\textwidth} %second row, second column bar chart
Top Products/Quantity
```{r, out.width="\\textwidth", fig.width=3.5,fig.height=1.8,fig.asp=NA}
g <- group_by(data, ProductName) %>%
summarize(qty = sum(Quantity)) %>%
arrange(desc(qty)) %>%
head(n = 5) %>%
ggplot(data = ., aes(x = reorder(ProductName, qty), y = qty)) +
geom_bar(stat = "identity", fill = "#fc9272", width = 0.5) +
coord_flip()
g + theme(
axis.text.y = element_text(size = rel(1), hjust = 0),
axis.text.x = element_text(size = rel(1), face = "bold"),
panel.background = element_rect(fill = "grey98"),
plot.background = element_rect(fill = "grey98"),
axis.title = element_blank(),
panel.border = element_blank(),
panel.grid.major.x = element_line(color = "gray90")
)
```
\end{column}
\hfill
\begin{column}{0.30\textwidth} %second row, third column bar chart
Top Products/Sales
```{r, out.width="\\textwidth", fig.width=3.5,fig.height=1.8,fig.asp=NA}
g <- group_by(data, ProductName) %>%
summarize(sales = sum(UnitPrice)) %>%
arrange(desc(sales)) %>%
head(n = 5) %>%
ggplot(data = ., aes(x = reorder(ProductName, sales), y = sales)) +
geom_bar(stat = "identity", fill = "#fc9272", width = 0.5) +
scale_y_continuous(labels = dollar) +
coord_flip()
g + theme(
axis.text.y = element_text(size = rel(1), hjust = 0),
axis.text.x = element_text(size = rel(1), face = "bold"),
panel.background = element_rect(fill = "grey98"),
plot.background = element_rect(fill = "grey98"),
axis.title = element_blank(),
panel.border = element_blank(),
panel.grid.major.x = element_line(color = "gray90")
)
```
\end{column}
\end{columns}
Just to recap: we have six boxes in two rows and three columns. The first box will show the top products as a table. The second box in the middle column will show the top customers. And the last box in the first row will show the top employees. The bottom row contains charts. The first one is monthly sales as a calendar heatmap products by quantity.
When everything goes smoothly after we run the master RMD document, knitr will knit the child document for each of the categories passed as an iterator (i) in the master document. The child document will filter the rows for this iterator and create a data set for all the calculations.
We will paste all the output from the knitted child documents into the out variable.
In the end, the inline command will print the concatenated result.
We get the results by clicking on the Knit button in RStudio. We should now get two pages, one per category, with all the six elements.
Here's the best part of this script. You may remember that there were eight categories, but our loop was for only two categories.
But if we change the code to go through all the rows from the cat_counts data frame, this for loop will go through each of those categories and knit a child document and put it in into our final presentation document. Eight pages for eight categories as shown in the image below.
```{r runall, include=FALSE}
out <- NULL
for (i in seq_len(nrow(cat_counts))) {
out <- c(out, knitr::knit_child('northwind-child-report.Rmd'))
}
```

Watch me go through this step-by-step tutorial in this video:
You can imagine the power of this method because you can make various changes to the charts and tables. You can create your own calculations. As long as they fit in these nice grid formats, you can create such automated reports, dashboards and analysis for any data set.
You don't have to change your calculations again; you just have to make sure that your calculations are right the first time. Even if your database gets updated, it gets refreshed, it has more data, all you have to do is just run the program again and it will produce the report every time. Imagine the same analysis, report or presentation done for you every month!
Another powerful benefit of this approach: you can connect to any data, you can reshape it, and still create nice-looking reports. Although we added LaTex specific code in this document, if you create a new markdown document with a presentation format or an article format, you can actually export it to a PDF or a Word document, even a PowerPoint presentation. These formats can then be imported into those applications. But I like the PDF format because it's highly scalable even when it is made really big, it doesn't lose its quality.
And that is why I love R because of these benefits!

[…] to Use OpenAI’s GPT-2 to Create an AI Writer November 26, 2019 Automated Reports and Dashboards in R November 24, 2019 Natural Language Generation with R (sort of) November 17, […]
[…] every dissertation had the same approach. I was confident that this part can be programmed with a template using RMarkdown and RStudio. Since repeating this type of analysis is hardly special, I hope that future […]
[…] I first started reading about dashboards and good chart design, I bumped into Stephen Few's book Information Dashboard Design. This […]
[…] There are other presentation options in RMarkdown and RStudio such as ioslides, slidy, and beamer, but for this post, we will focus on PowerPoint […]