

Undoubtedly, the New York Times publishes the best data visualizations and infographics that are data intensive, yet are elegant. The elegance comes from carefully studying the data, identifying the key patterns and simplifying the graphics to show these patterns or trends.
Here’s what Amanda Cox, editor of The Upshot, said in an interview “we probably pay more attention to things like typography and design, which, done properly, are really about hierarchy and clarity, and not just about making things cute.”
“we probably pay more attention to things like typography and design, which, done properly, are really about hierarchy and clarity, and not just about making things cute.
Amanda Cox
Two phrases worth repeating from her quote: “clarity” and “not just about making things cute.” As analysts, we often celebrate “interesting” things, which really are shiny objects with hardly any actionable information. Interesting is not actionable. NYT’s data visualizations may not be “cute,” but they certainly make information accessible, increasing the chances of action. Paraphrasing Wayne Gretzky: You waste 100% of your analysis or data visualizations that the readers don’t take action on.
Although the interactive data visualizations on the New York Times website are crazily better than the static charts, they require more work and knowledge of JavaScript frameworks.
For this article, we will produce a static chart.
I saw this graphic in a sobering article on suicide rates in the US. The article says — and the graphs clearly show — that the suicide rates have gone up in every age group, except for older adults.
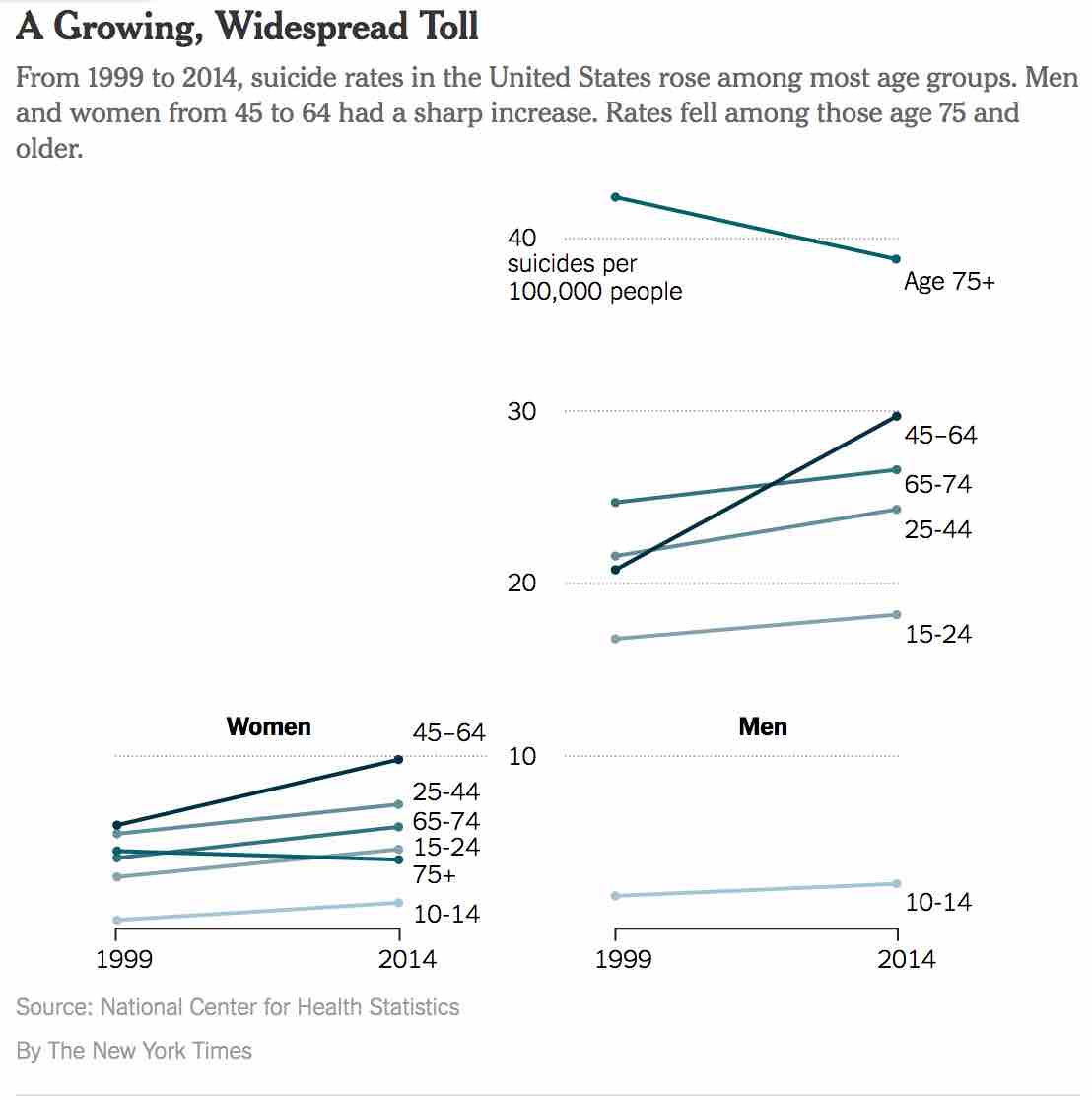
From 1999 to 2014, the 30-year period studied in the article, the overall suicide rate went up by 24%.
24%???
That’s shocking! More than 42,000 people committed suicide in 2014, compared with 29,199 in 1999. In 2014, death by suicide was the ninth leading cause of deaths in the US.
You don’t need to study all the numbers to see that the rates have gone up: data visualizations make this observation unforgettable.
How do we go about creating such a infographic? That’s what I wanted to find out.
I thought this was a type of a parallel coordinate plot, but if you look at it again, it is actually a line graph. Something ggplot can easily handle.
Step 1: Load Libraries
I loaded all my favorite libraries, with much gratitude to Hadley Wickham:
-
ggplot2for plotting, of course reshape2for transforming the data frameggthemesto get beautiful themes for ggplot without writing all the customizationdirectlablesto insert annotations and legendsstringrfor some simple string manipulation
library(ggplot2) library(reshape2) library(ggthemes) library(directlabels) library(stringr) |
Step 2: Data Manipulation
Yes, I could fetch the data from CDC’s site. Since I just wanted to build a proof-of-concept, I eyeballed the numbers on the plot for the overall suicide rates.
suicides <- data.frame(age_group = c('15-24', '25-44', '45-64', '65-74', '75+'), t1999 = c(15,21,20,25,42), t2014 = c(18,23,30,26,39)) |
I read the data this way because it is easier to write them in one line than concatenate all the rows. Plus, I get to use some reshape magic.
suicides <- melt(suicides, id.vars = "age_group", variable.name = "year", value.name = "deaths") |
With melt, we can make the wide data narrow i.e. bring columns as rows. Here, I created rows for each year and age group.
Now that we have the year field with values of t1999 and t2014, we will convert them to numbers. I had to add some text before the variable name because R doesn’t allow column names that start with a number.
suicides$year <- as.numeric(substr(suicides$year, 2,5)) |
Step 3: Selecting a Theme
Now for some fun. The package ggthemes provides many themes that make generating nice plots very easy. This package saves a lot of time because you don’t have to a) find the right parameter to adjust and b) find the “good” values for those parameters. For example, you may want to change the way axis labels look. The parameter for that axis.text in the theme function. But, then you have to rely on element_text to actually change the property. These are very nice features, really. It just takes a lot of time to find and add the values that look good.
So, for this chart, I applied all the themes to see what the basic graph looked like. You can use this command to find out all the themes.
ls("package:ggthemes")[str_detect(ls("package:ggthemes"), "theme_")] |
## [1] "theme_base" "theme_calc"
## [3] "theme_economist" "theme_economist_white"
## [5] "theme_excel" "theme_few"
## [7] "theme_fivethirtyeight" "theme_foundation"
## [9] "theme_gdocs" "theme_hc"
## [11] "theme_igray" "theme_map"
## [13] "theme_pander" "theme_par"
## [15] "theme_solarized" "theme_solarized_2"
## [17] "theme_solid" "theme_stata"
## [19] "theme_tufte" "theme_wsj"
Ironically, theme that got me the closest result was the Wall Street Journal theme. Weird! I know.
Step 4: Building the NYT Like Data Visualization
Create the basic plot
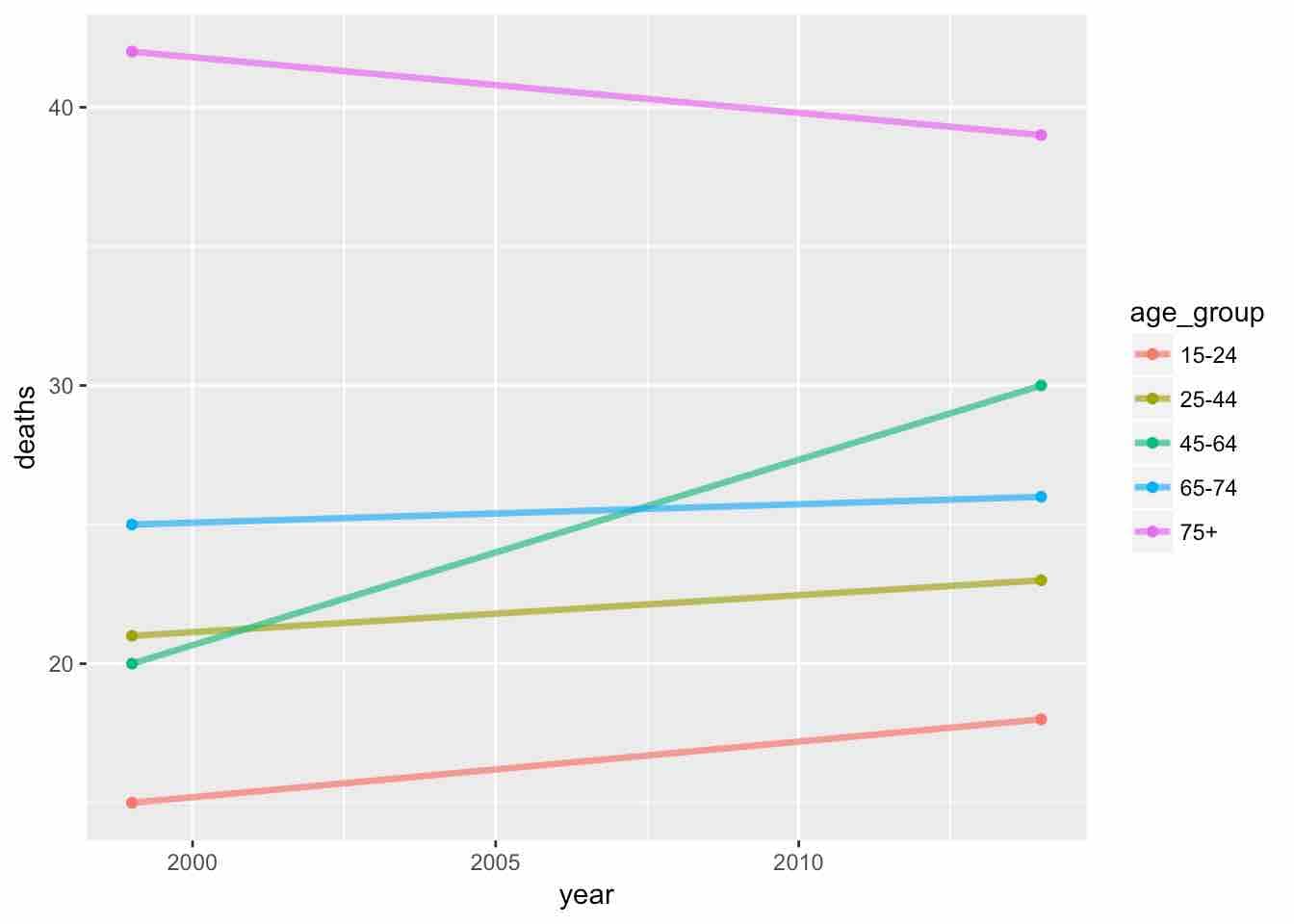
It is really a line plot, so we create a plot with year on the x-axis and deaths on the y-axis. We also add colors using the age group variable. All these are parameters for the aes function. We want to make the lines little bit thicker and make the colors translucent. We do so with this command:
g <- ggplot(data = suicides, aes(x = year, y = deaths, color = age_group)) + geom_line(size = 1.2, alpha = 0.7) |
The resulting graph looks like this:

and your reaction might be:

Well, hold on. We are making this chart better one step at a time.
Let’s add the “circles” at the end:
g <- g + geom_point() |
With circles at the end:
Change the Line Colors
You can manually assign colors to each of the age group value with this command.
g <- g + scale_color_manual(values = c("45-64" = "black", '15-24' = "darkturquoise", '25-44' = "darkturquoise",'65-74' = "darkturquoise", '75+' = "darkturquoise")) |
Now with changed line colors:

I played with a few colors before I decided on darkturquoise, which I knew, of course, because that’s how cool I am 🙂
To find all the named colors in R, you can use the colors() function. You can also use a website like http://imagecolorpicker.com/ to find the colors in an image.
head(colors()) |
## [1] "white" "aliceblue" "antiquewhite" "antiquewhite1"
## [5] "antiquewhite2" "antiquewhite3"
Modify the Axes
We will use the scale_*_continuous function to add breaks, set axis limits, and trim the extra space around axis labels.
g <- g + scale_x_continuous(breaks = c(1999, 2014), limits = c(1999, 2014.5), expand = c(0, 1)) + scale_y_continuous(breaks = c(20, 30, 40)) |
After changing the axes properties:

Apply the WSJ Theme
This is straightforward. We just add the function theme_wsj from the ggthemes package to our plot.
g <- g + theme_wsj() |
Creating a chart like this:
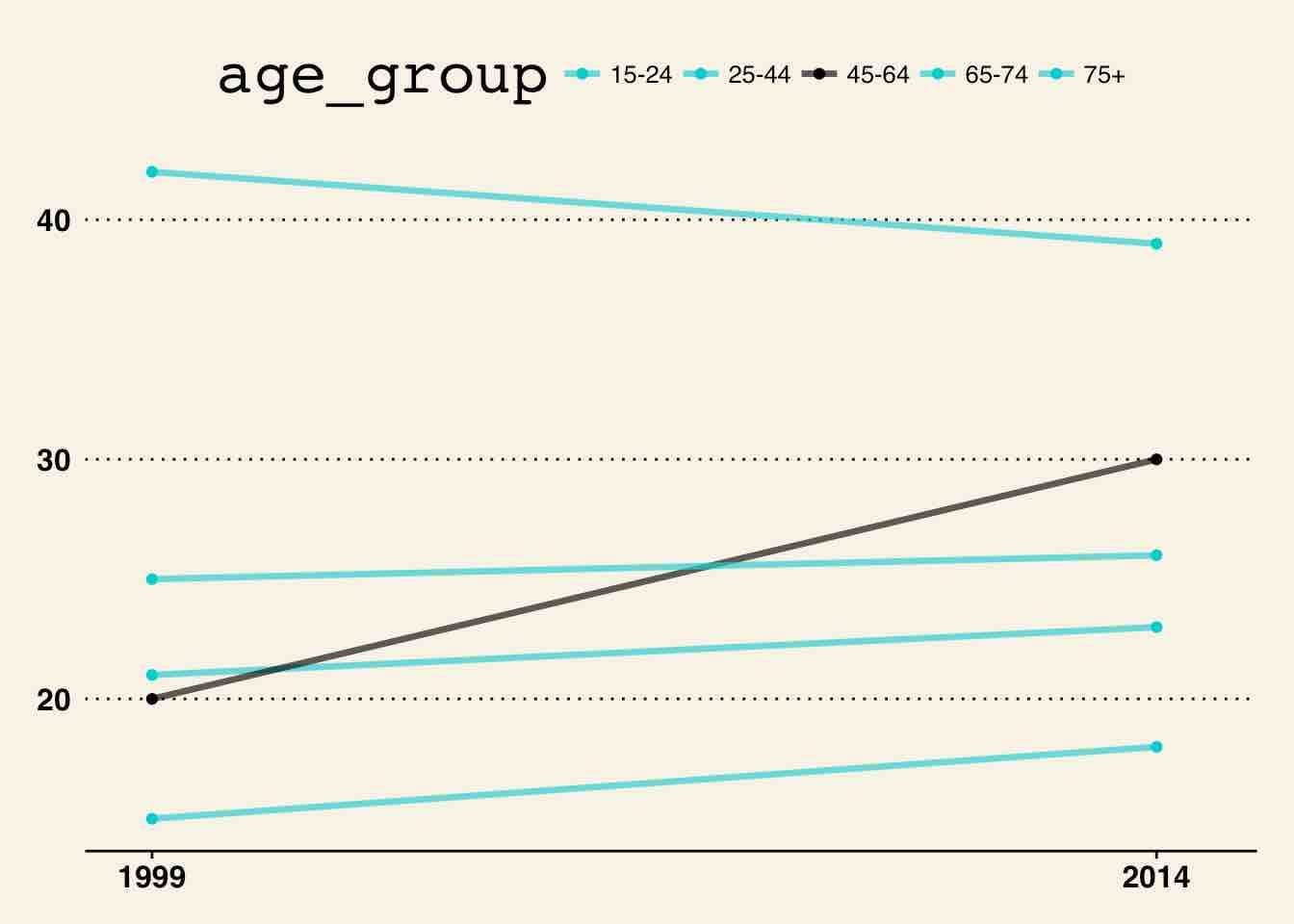
Add Text Annotations
We will use the annotate function from ggplot to add custom text labels at the desired locations. I chose some positions that looked good. You may want to change them.
Here is how it looks:
g <- g + annotate("text", x = 2000.5, y = 38, label = "suicides per\n 100,000 people") g <- g + annotate("text", x = 2014, y = 43, label = "Age\nGroup", size = 3, fontface = "bold", hjust = .2) |

Remove the Legend and Clean up the Background
g <- g + theme(legend.position = "none", plot.background = element_rect(fill = "white"), panel.background = element_rect(fill = "white")) |
After cleaning up:

Add Line Legends
We will also use the geom_dl function from the directlabels package to add text annotations at the end of the lines. This is really a best practice: rather than placing legends on the chart and make the reader match all the legend colors with the line values, placing the labels next to the lines makes it very easy for the reader to access the information.
g <- g + geom_dl(aes(label = age_group, x = year + 0.2), method = "last.qp", cex = 0.5) |
After the labels:

Make the Axis Ticks Visible
Like the NYT chart, we will make the axis ticks thicker as well as longer.
NYT like axis ticks:
g <- g + theme(axis.ticks.x = element_line(size = 1), axis.ticks.length=unit(0.2,"cm")) |
And that’s it. We are done. Here’s how our final chart looks like:

print(g) |
Save your version of the NYT Data Visualization
You can use the convenient wrapper ggsave function to save this plot to a png.
ggsave(filename = "NYT_Suicide_Rates.png", plot = g, width = 4, height = 4) |
It took a few steps, but we got pretty close to the original NYT data visualization. A great thing about this approach: this is reproducible and repeatable, something that I mentioned while comparing Tableau and R. When you are working in teams, it becomes critical that others know how you completed a task. It is equally important even when you are working by yourself as our memory as not as strong as we claim it to be.
There you have it: a NYT data visualization using R with many thanks to Hadley Wickham and other R contributors. The ggplot library is very extensive and you can achieve many things, but the biggest roadblock is finding the parameters for the right functions or aesthetics. If you are stuck, stackoverflow is a great option and as is the ggplot documentation.
I hope this gives you many ideas and I’d love to know what you think about this approach.
Here’s the complete R script:
library(ggplot2) library(reshape2) library(ggthemes) library(directlabels) library(stringr) suicides <- data.frame(age_group = c('15-24', '25-44', '45-64', '65-74', '75+'),t1999 = c(15,21,20,25,42),t2014 = c(18,23,30,26,39)) suicides <- melt(suicides, id.vars = "age_group", variable.name = "year", value.name = "deaths") suicides$year <- as.numeric(substr(suicides$year, 2,5)) ls("package:ggthemes")[str_detect(ls("package:ggthemes"), "theme_")] g <- ggplot(data = suicides, aes(x = year, y = deaths, color = age_group)) + geom_line(size = 1.2, alpha = 0.7) + geom_point() g <- g + scale_color_manual(values = c("45-64" = "black", '15-24' = "darkturquoise", '25-44' = "darkturquoise",'65-74' = "darkturquoise", '75+' = "darkturquoise")) g <- g + scale_x_continuous(breaks = c(1999, 2014), limits = c(1999, 2014.5), expand = c(0, 1)) + theme_wsj() g <- g + scale_y_continuous(breaks = c(20, 30, 40)) g <- g + annotate("text", x = 2000.5, y = 38, label = "suicides per\n 100,000 people") g <- g + annotate("text", x = 2014, y = 43, label = "Age\nGroup", size = 3, fontface = "bold", hjust = .2) g <- g + theme(legend.position = "none", plot.background = element_rect(fill = "white"), panel.background = element_rect(fill = "white")) g <- g + geom_dl(aes(label = age_group, x = year + 0.2), method = "last.qp", cex = 0.5) g <- g + theme(axis.ticks.x = element_line(size = 1), axis.ticks.length=unit(0.2,"cm")) print(g) ggsave(filename = "NYT_Suicide_Rates.png", plot = g, width = 4, height = 4) |
What do you think?
This is great! Thank you, I am going to share immediately with my team.
My question: do you have any thoughts or recommended resources on the theory of design for plots? It’s one thing to copy a plot, but when building my own, there’s probably 20 things that I would never think to consider. For me, that is often when to include text on a plot, for example.
Do you have any bullet points or key ideas for what to aesthetically consider when building a plot from scratch?
Thanks!
Hi, Jonathan,
Thanks for your note. I’m working on a detailed guide for better data visualizations. Meanwhile, 1. you can subscribe using the form in this post to get a cheat sheet. 2. watch this presentation in which I walkthrough some principles of effective data viz: https://youtu.be/tq7cjomwFmY
3. To summarize all of this: remember these four Cs: Clarity, Concision, Compression, and Contrast. I will write more about these four Cs as well as provide more resources.
[…] to Create a Wall Street Journal Data Visualization in R April 12, 2017 How to Create a Data Visualization from the New York Times in R February 20, 2017 Mapping Walmart Growth Across the US using R October 11, […]
[…] example below is a visualization created to help people in Japan evaluate the seismic risk of their area in the event of an earthquake. […]